
1. K-익명성
[정의] 주어진 데이터 집합에서 준식별자 속성값들이 동일한 레코드가 적어도 K개 존재하도록 하는 연결공격(Linkage Attack) 방어형 프라이버시 보호 모델
[필요성] 개인식별 위험 증가, 개인정보 침해 최소화
[내용] 특정인임을 추론할 수 있는지 여부를 검토, 일정 확률수준 이상 비식별 되도록 함.
(동일한 값을 가진 레코드를 k개 이상 으로 함. 이 경우 특정 개인을 식별할 확률은 1/k임)
[추가적인 평가모델] k익명성, l다양성, t근접성
[재식별 공격기법과 프라이버시 보호 모델]
-연결공격: 비식별조치된 결과와 다른 공개데이터간 결합을 통해 개인을 식별하는 공격.(‘k-익명성’으로 검토)
-동질성공격: 범주화된 k-익명성 데이터 집합에서 동일한 정보를 이용하여 대상의 정보를
알아내는 공격 (‘l-다양성’으로 검토)
-배경지식공격: 공격자의 배경 지식을 통해 대상의 민감정보를 알아내는 공격(‘l-다양성’으로 검토)
-쏠림공격: 정보가 특정한 값에 쏠려있는 경우 확률적으로 대상의
민감 정보를 추론할 수 있는 공격(‘t-근접성’으로 검토)
-유사성공격: 비식별 조치된 정보가 서로 다르지만 의미상 유사하다면 민감 정보를 유추할 수 있는 공격
(‘l-다양성’으로 검토)
2. L-다양성
[정의] 주어진 데이터 집합에서 함께 익명화 되는 레코드들(동질집합)은 적어도 L개의 서로 다른 민감정보를 가져야한다는 프라이버시 보호모델
[내용] 특정인 추론이 안된다고 해도 민감한정보 와 다양성을 높여 추론 가능성을 낮추는 기법.
(각 레코드는 최소 1개 이상의 다양성을 가지도록 하여 동질성 또는 배경 지식 등에 의한 추론 방지)
[구현방법] 익명화 과정에서 동질집합 내 민감정보는 L개 이상의 서로 다른 정보를 갖도록 구성
[사례]
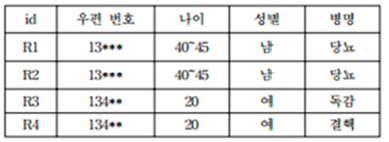
- 부하직원인 홍길동이 사는 동네(우편번호13490),나이(41세),성별(남)을 알고 있는 경우 R1, R2중
하나가 홍길동임을 알 수 있고, 동질집합 내 병명이 당뇨로 민감정보 추론가능.
3. T-근접성
[정의] 동질집합에서 민감정보의 분포와 전체 데이터 집합에서 민감정보의 분포가 유사한 차이를 보이게 하는 프라이버시 보호모델
[내용] L-다양성 뿐만 아니라, 민감한 정보의 분포를 낮추어 추론 가능성을 더욱 낮추는 기법.
(전체 데이터 집합의 정보 분포와 특정 정보의 분포 차이를 t이하로 하여 추론 방지)
[구현방법]
- 전체 데이터 분포와 유사하도록 동질집합 데이터 분포를 구성
- 민감정보가 특정값으로 쏠리거나 뭉치지 않도록 데이터 구성
[사례]
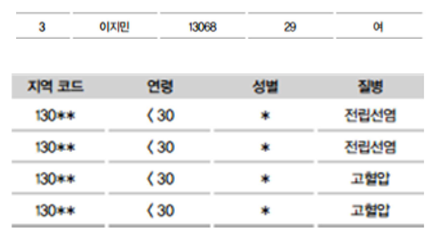
- "여자는 전립선염에 걸릴수 없다"등의 배경지식을 통해 민감정보를 알아내는 공격
1) 선거인명부에서 이지민의 정보를 얻음 (지역코드 13068, 나이 29세)
2) 지역코드 130..., 연령 30 이하 동질그룹에서 "여자는 전립선염에 걸릴수 없다"는 배경지식을
이용해 이지민의 병명은 고혈압임을 알아냄
'ITPE > 보안' 카테고리의 다른 글
| Feistel (0) | 2021.03.28 |
|---|---|
| 프라이버시 보존형 데이터 마이닝(PPDM) (0) | 2021.03.28 |
| 개인정보영향평가(Privacy Impact Assessment) (0) | 2021.03.27 |
| SSO, EAM, IAM (0) | 2021.03.27 |
| GDPR (General Data Protection Regulation) (0) | 2021.03.27 |